DDPO: Aligning Diffusion Models with Human Preferences via Reinforcement Learning
Published:
Mainstream AIGC models, like ChatGPT and Stable Diffusion, have been drawing much attention over the recent years. Despite the massive amount of high-quality dataset, advanced network structure and loads of GPUs, one innegligible factor that contributes to their success is the use of RLHF, or reinforcement learning from human feedback. This blog is mostly based on a paper in May 2023 by the Levine Lab at UCB, and probes into how RLHF can be elegantly integrated into diffusion framework.
Basics
Before we start, we may as well have a grasp of what is diffusion model and RLHF, and how they work.
Diffusion
On the basis of its daily usages, diffusion model learns to generate images via first gradually adding Gaussian noise to an original one until completely destroying it and turning it into a pure Gaussian noise, and then trying to recover the image from the noise. Unlike popular choices for generative tasks in the past like GAN, diffusion provides an unsupervised, or more exactly, self-supervised manner of training, which is less demanding since there is no need for a data pair with extra annotation workload.
More generally, diffusion model leans a mapping that can go from a starting probability density function (PDF, usually Gaussian) to, theoretically, a desired, arbitrary one. My blog post back in Oct. last year have provided some interesting insights into approximating a PDF via score-matching, which is a less usual perspective for understanding diffusion models. Have a look if you’re interested.
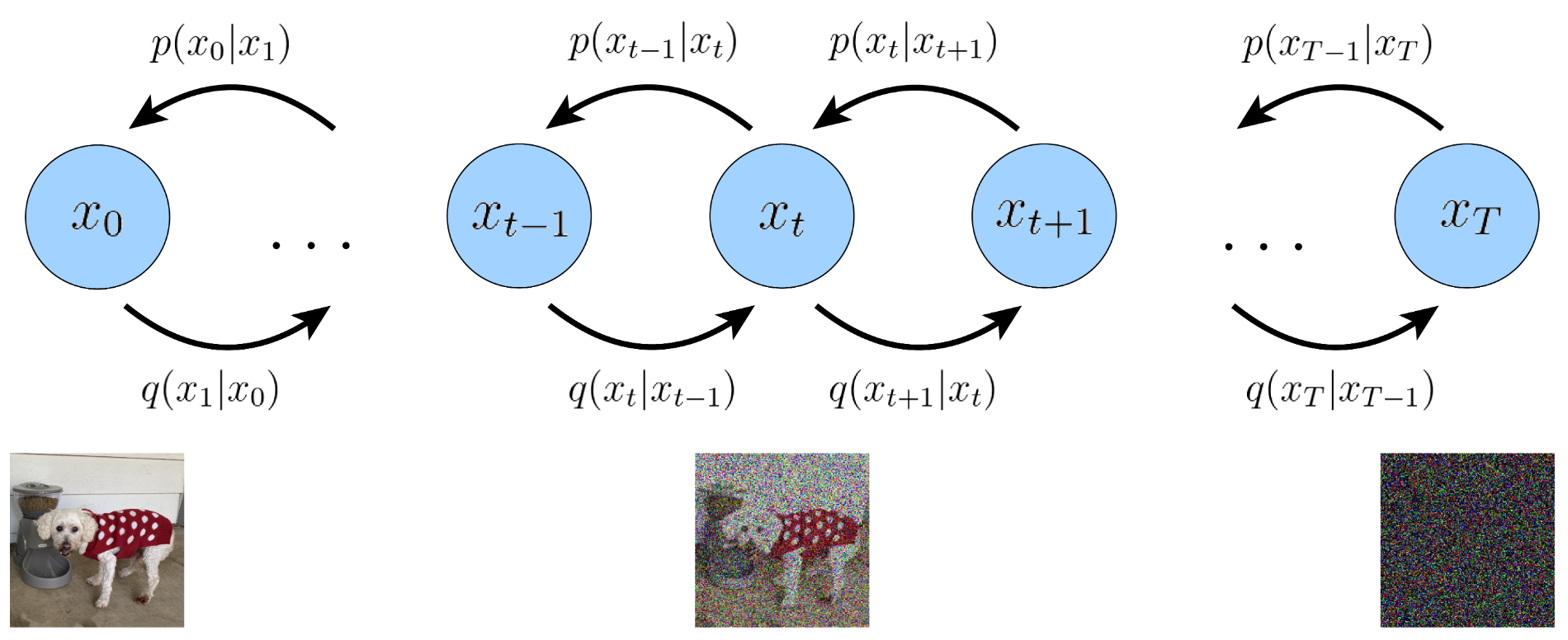
RLHF
As its name suggests, RLHF aims to align an intelligent agent’s perception to human preferences via the paradigm of RL, using human feedback as at least part of its supervision. The intelligent agent is usually a pretrained generative model, and an extra reward model is trained on human feedbacks collected that are for the samples generated by the pretrained model, or we can simply integrate human feedbacks into the RL system as rewards - as long as you don’t mind heavy labelling of each sample generated. And this is why I say “part of” - to promote efficiency, the popular choice is to train a reward model that can mimic human perception as reliable as possible.

Currently popular generative models, despite their prowess to generate visually realistic images, texts, etc., still fail to provide serious productivity that can be much more meaningful and exacting than entertainment, especially for safe-sensitive applications like medical imaging. One possible workaround may lie in improvement of the design of training loss. Most diffusion models, for example, utilize MSE as their loss function, and it often leads to oversmoothing particularly when the number of training epochs is not large enough. However, to design a loss function that can offer very human-like assessment for the samples, and at the same time is differentiable and easy to compute for optimization of the model, is outrageously difficult. Perceptual loss may be one feasible option, but aligning feature maps cannot guarantee the model’s similarity to how human feel about the samples - how can we know the “feature map” in our brain?
Out of this concern, RLHF seems to be a solution that is not perfect, but at least better - how about using human ourselves as supervision, and modeling our response and comments to the model’s inference as some kind of reward. Then the idea of RL can be brought in here.
Integration: DDPO
For a model with parameter $\theta$, the goal is to maximize the reward signal, i.e.,
\[\theta^\star = \arg \max_\theta \mathbb{E}_{\mathbf{x}_0 \sim p_\theta(\cdot \mid \mathbf{c})} [r(\mathbf{x}_0 \mid \mathbf{c})].\]Herein $\mathbf{c}$ is the condition for our diffusion model, and $r(\cdot)$ is the reward function. One na"ive way to combine the goal with diffusion optimization may be a single evaluation and then backpropagation. However, recall the denoising procedure of a diffusion model, and we can find that it contains multiple timesteps. This can be regarded as a trajectory, a concept defined in RL that consists of a series of states ad actions. To embed the diffusion denoising procedure into RL framework, we need to first formulate a corresponding MDP for it.
- State: the current noisy image $\mathbf{s}=\mathbf{x}_t$.
- Action: the next denoised image $\mathbf{a}=\mathbf{x}_{t-1}$
- Policy: \(\pi(\mathbf{a}_t\mid \mathbf{s}_t)=p^{\text{diffusion}}_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{x}_t, \mathbf{c}\right)\) decides the next action given the current state, exactly what we want to optimize.
- Reward: see below; after each action/state, zero until the last step of denoising is complete.
Then the entire trajectory can be presented as $\tau$. The optimization goal is then written as
\[\mathcal{J}(\theta)=\mathbb{E}_{\tau \sim p(\cdot \mid \pi)}\left[\sum_{t=0}^T R\left(\mathbf{s}_t, \mathbf{a}_t\right)\right] = \mathbb{E}_{\mathbf{x}_0 \sim p_\theta(\cdot \mid \mathbf{c})} \left[r(\mathbf{x}_0 \mid \mathbf{c})\right].\]With the formulation above, now policy gradient optimization methods can be applied. Let’s start from REINFORCE. Diffusion models can generally serve as score function estimator, and the score estimator of an arbitrary function $f(\mathbf{x})$ is written as
\[\begin{align} \nabla_\theta \mathbb{E}_{p_{\theta}}[f(\mathbf{x})] &= \nabla_\theta \int p_{\theta}(\mathbf{x}) f(\mathbf{x}) d\mathbf{x} \\ &= \int \nabla_\theta p_{\theta}(\mathbf{x}) f(\mathbf{x}) d\mathbf{x} \\ &= \int \frac{p_{\theta}(\mathbf{x})}{p_{\theta}(\mathbf{x})} \nabla_\theta p_{\theta}(\mathbf{x}) f(\mathbf{x}) d\mathbf{x} \\ &= \int p_{\theta}(\mathbf{x}) \frac{\nabla_\theta p_{\theta}(\mathbf{x})}{p_{\theta}(\mathbf{x})} f(\mathbf{x}) d\mathbf{x} \\ &= \int p_{\theta}(\mathbf{x}) \nabla_\theta \log p_{\theta}(\mathbf{x}) f(\mathbf{x}) d\mathbf{x} \\ &= \mathbb{E}_{p_{\theta}} \big[ \nabla_\theta \log p_{\theta}(\mathbf{x})f(\mathbf{x}) \big]. \end{align}\]Combined with the MDP framework, the policy gradient can be given by
\[\nabla_\theta \mathcal{J}(\theta) = \mathbb{E}_{\tau \sim p_\theta(\tau)} \left[\left(\sum^T_{t=0} \nabla_\theta \log \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \right) \left(\sum^T_{t=0}R(\mathbf{s}_t, \mathbf{a}_t) \right) \right].\]This gradient is usually referred to as the REINFORCE gradient, and with this, we can update our model via gradient ascent
\[\theta \leftarrow \theta + \alpha \nabla_\theta \mathcal{J}(\theta).\]However, the expectation $\mathbb{E}{\tau \sim p\theta(\tau)}$ is for all possible trajectories and we cannot take all of them. So it should be estimated with only the sampled trajectories in the current batch instead. Also, a loss function can be constructed from the gradient given above
\[\mathcal{L}(\theta) = \mathbb{E}_{\tau \sim p_\theta(\tau)} \left[ - \left(\sum^T_{t=0} \log \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \right) \left(\sum^T_{t=0}R(\mathbf{s}_t, \mathbf{a}_t) \right) \right],\]and then we don’t need to calculate the gradient and pass it to the optimizer manually. One intuition is that, the loss function looks like a negative log-likelihood function, with actions as the targets. The difference lies in that it is weighted by the rewards. The loss then, as you can guess, tries to lead the model on a high-reward trajectory.
Subtituting the notations with ones in the diffusion framework, we can get a more easy-to-understand objective for the optimization
\[\nabla_\theta \mathcal{J}(\theta) = \mathbb{E} \left[\left(\sum^T_{t=0} \nabla_\theta \log p^\text{diffusion}_\theta\left(\mathbf{x}_{t-1} \mid \mathbf{c}, t, \mathbf{x}_t\right) \right) r(\mathbf{x}_0, \mathbf{c}) \right].\]One challenge with this approach is that for each optimization step, the sampling from the current iteration of the model needs to be performed, and we need to re-calculate $\mathbf{x}_t$ as it comes from the current version of the model. This is very computationally demanding and wasteful, as the samples collected with previous iterations of the model cannot be used to learn.
One trick to address this is known as importance sampling. This relies on the following identity
\[\mathbb{E}_{x\sim p(x)} \left[f(x)\right] = \mathbb{E}_{x\sim q(x)} \left[\frac{p(x)}{q(x)}f(x)\right].\]Applying importance sampling to the gradient, we have
\[\begin{aligned} &\quad\nabla_\theta \mathcal{J}(\theta) \\ &= \mathbb{E}_{\tau \sim p_{\theta_{old}} \left(\tau \right)} \left[\left(\sum^T_{t=0} \frac{\pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right)}{\pi_{\theta_{old}}\left(\mathbf{a}_t \mid \mathbf{s}_t\right)} \nabla_\theta \log \pi_\theta\left(\mathbf{a}_t \mid \mathbf{s}_t\right) \right) \left(\sum^T_{t=0}R(\mathbf{s}_t, \mathbf{a}_t) \right) \right]. \end{aligned}\]Again, we replace the notations with ones from the diffusion framework and we have
\[\mathcal{L}(\theta) = \mathbb{E} \left[ - \sum^T_{t=0} \frac{p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)}{p^\text{diffusion}_{\theta_{old}}(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)} r(\mathbf{x}_0,\mathbf{c}) \right].\]Minimization of this loss function is equivalent to gradient with the following gradient
\[\hat g = \mathbb{E} \left[\sum^T_{t=0} \frac{p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)}{p^\text{diffusion}_{\theta_{old}}(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)} \nabla_\theta p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t) r(\mathbf{x}_0,\mathbf{c}) \right].\]Note that reward $r(\mathbf{x}_0,\mathbf{c})$ is usually normalized in practice to provide better convergence, and the normalized version is called advantage $A(\mathbf{x}_0, \mathbf{c})$1. In addition, we don’t want current policy diverge too much from the previous policy, otherwise chances are that we may diverge and get a bad policy. So clipping is adopted for the sampling ratio of the loss function.
\[L(\theta) = \mathbb{E} \left[ - \sum^T_{t=0} \min \left(\frac{p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)}{p^\text{diffusion}_{\theta_{old}}(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)} A(\mathbf{x}_0,\mathbf{c}), \mathrm{clip} \left( \frac{p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)}{p^\text{diffusion}_{\theta_{old}}(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t)}, 1-\epsilon, 1+\epsilon \right) A(\mathbf{x}_0,\mathbf{c}) \right) \right].\]The loss function can be written in a way that’s numerically easier to calculate/more stable (using logs, ignoring the clipping for now)
\[L(\theta) = \mathbb{E} \left[ - \sum^T_{t=0} \exp{\left(\log p^\text{diffusion}_\theta(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t) -\log p^\text{diffusion}_{\theta_{old}}(\mathbf{x}_{t-1} | \mathbf{c},t,\mathbf{x}_t) \right)} A(\mathbf{x}_0,\mathbf{c}) \right].\]Original DDPO also clips the advantages, but not described in the paper. ↩