Reinforcement Learning
Published:
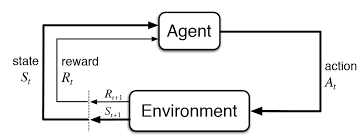
Reinforcement learning is a machine learning training method based on rewarding desired behaviors and/or punishing undesired ones. In general, a reinforcement learning agent is able to perceive and interpret its environment, take actions and learn through trial and error.
What is RL
Definitions
- Learn how to map states to actions, so as to maximize a numerical reward over time
- A multi-stage, often Markovian, decision-making process
- Agents must learn by trial-and-error; not entirely supervised, but interactive
- Actions may affect not only the immediate reward but also subsequent rewards: delayed effect
Types of Learning
Supervised Learning
- Training data: (X, Y) → (feature, label)
- To predict Y, minimizing some loss
- e.g., Regression, Classification
Unsupervised Learning
- Training data: (X) → (feature only)
- To find “similar” points in high-dim X-space
- e.g., Clustering
Reinforcement Learning
- Training data: (S, A, R) → (State-Action-Reward)
- To develop an optimal policy (sequence of decision rules) for the learner so as to maximize its long-term reward
- e.g., Robotics, Board game playing program
Relationships Between RL and MDP
In Reinforcement Learning (RL), the problem to resolve is described as a Markov Decision Process (MDP). Theoretical results in RL rely on the MDP description being a correct match to the problem. If your problem is well described as a MDP, then RL may be a good framework to use to find solutions.
RL is a technique to learn an MDP and solve it for the optimal policy at the same time.
An RL problem can be represented using an MDP as a 5-tuple $(S, A, T, R, \gamma)$:
- A set of states $S$: A state $s$ is the situation in which the agent finds itself
- For an agent who is learning to walk, the state would be position of its 2 legs
- For an agent playing chess, the positions of all the pieces on the board would be the state
- Set of actions (per state) $A$. An action is what an agent can do in each state
- Given the agent who is learning to walk, the actions would include taking steps within a certain distance.
- Transitions $T(s, a, s^{\prime})$, mapping the state-action pair at time $t$ to its resulting states.
- It specifies the probability that environment would transition to $s^{\prime}$, if the agent takes the action $a$ when it is in state $s$.
- Reward function $R(s, a, a^{\prime})$, representing the rewards for a particular transition.
- It is basically a feedback from the environment and measures the success or failure of an agent’s actions
- e.g., when Mario touches some coins he wins positive reward.
- Discount Factor $\gamma ∈ [0,1]$, where lower values emphasize immediate rewards.
- It makes future rewards worth less than immediate rewards so that the agent does not delay necessary actions.
If the MDP is episodic, i.e., the state is reset after each episode of length $T$, then the sequence of states, actions and rewards in an episode constitute a trajectory of the policy. Every trajectory of a policy accumulates rewards from the environment, resulting in the return
\[R=\sum_{i=0}^{\infty}\gamma^i\times r_{t+i+1}\]where $r_{t+i+1}$ represents the reward for transitioning from $s_{t+i}$ to $s_{t+i+1}$
A policy $\pi$ is the strategy that the agent employs to determine the next action based on the current state. It maps a state to an action
\[a = \pi(s)\]Value function $V^{\pi}(s)$ measures the expected total return (sum of future discounted reward) with starting state as $s$
\[V^{\pi}(s)=E[R_t\mid S_t=s]\]Q-value $Q^{\pi}(s, a)$ is the expected total return of taking action $a$ at state $s$, and then continue according to $\pi$
\[Q^{\pi}(s, a)=E[R_t\mid S_t=s, A_t=a]\]The goal of RL is to find an optimal policy, $\pi^{\ast}$, which achieves the maximum expected return from all states
\[\pi^*=\operatorname{argmax}\lim_\pi E[R \mid \pi]\]For non-episodic MDPs, where $T=\infty$, $\gamma$ is set to be $<1$ to prevents from accumulating an infinite sum of rewards.
Bellman Equation
Back to the value function, How can we calculate it? To simplify it, it can be decomposed into 2 parts
- Instant reward $r_{t+1}$
- discounted value function for subsequent states $\gamma\times V(s_{t+1})$
Then Bellman equation can be derived as follows
\[\begin{aligned} V^{\pi}(s)&=E[R_t\mid S_t=s]\\ &=E\left[\sum\limits_{i=t+1}\gamma^{i-t-1}r_{i}\mid S_t=s\right]\\ &=E\left[r_{t+1}+\gamma\sum\limits_{i=t+2}\gamma^{i-t-2}r_{i}\mid S_t=s\right]\\ &=E\left[r_{t+1}+\gamma R_{t+1}\mid S_t=s\right]\\ &=E[r_{t+1}+\gamma V^{\pi}(S_{t+1})\mid S_t=s]\\ &=\sum\limits_a\pi(s, a)\sum_{s^{'}}p^a_{ss^{\prime}}\left[r^a_{ss^{\prime}}+\gamma V^{\pi}(s^{\prime})\right] \end{aligned}\]Similar equation holds for Q-value
\[\begin{aligned} Q^{\pi}(s, a)&=E[r_{t+1}+\gamma Q^{\pi}(S_{t+1}, A_{t+1})\mid S_t=s, A_t=a]\\ &=\sum\limits_{s^{\prime}}p^a_{ss^{\prime}}\left[r^a_{ss^{\prime}}+\gamma\sum\limits_{a^{\prime}}Q^{\pi}(s^{\prime}, a^{\prime})\right] \end{aligned}\]where $p^a_{ss^{\prime}}$ stands for transition probability from $s$ to $s^{\prime}$, and $r^{a}_{ss^{\prime}}$ represents the reward for taking action $a$ and transitioning from $s$ to $s^{\prime}$
Optimal Bellman Equation
For an optimal policy $\pi^{\ast}$, $V^(s)=\max\limits_aQ^(s, a)$
\[\begin{aligned} V^*(s)&=\max\limits_aE[r_{t+1}+\gamma Q^{\pi}(S_{t+1}, A_{t+1})\mid S_t=s, A_t=a]\\ &=\max\limits_a\sum\limits_{s^{\prime}}p^a_{ss^{\prime}}\left[r^a_{ss^{\prime}}+\gamma\sum\limits_{a^{\prime}}Q^{\pi}(s^{\prime}, a^{\prime})\right] \end{aligned}\]Model-based or Model-free
In most real-world scenarios, the agent doesn’t know $T, R$ a priori, so how to find the optimal policy?
- Model-based: the agent can learn a model of the environment, i.e., $T, R$, from its observations.
- If the agent is currently in state $s_1$ and takes action $a_1$, the environment transitions to $s_2$ and gives reward $r_2$. This information will be used to improve the current estimate of $T(s_2\mid s_1, a_1)$ and $R(s_1, a_1)$. Based on a learned model, a planning algorithm can be used to find a good policy.
- Model-free: a policy can then be derived by choosing the action with the highest Q-value in the current state. So it may not be necessary to learn the model in order to learn a good policy.
Off-policy or On-policy
There is a famous exploration vs exploitation dilemma in RL and an agent must strike a balance between the two phenomenon. Exploitation is to make the best decision given the current information, while exploration is gathering more information.
To start with, let’s first figure out what’s behavior policy and what’s target policy
Behavior policy or Target policy
- Behavior policy refers to policy the agent uses to determine its action in a given state. So it’s in charge of selecting actions for the agent.
- Target policy refers to policy the agent uses to learn from rewards received for its actions which are used to update Q-value.
In terms of On-policy, its behavior and target policies share the same policy, which is simpler for implementation but may lead to local optimization. While Off-policy separates behavior policy and target policy, which keeps exploration but is harder to optimize.
Online or Offline
Primary Cost
Cost: path → action space
What is DRL
Perception, and representation of the environment is one of the key problems that must be solved before the agent can decide to select an optimal action to take. In RL tasks, usually a human expert provides features of the environment based on his knowledge of the task. This causes the lack of scalability and is hence limited to low-dimensional problems.
The powerful representation learning properties of deep neural networks has offered new methodology for these problems, as they can overcome the curse of dimensionality, by automatically finding compact low-dimensional representations/features of high-dimensional data. Typically, deep neural networks solve the problem of perception and representation of the environment.
References
http://www.cs.cmu.edu/~10601b/slides/MDP_RL.pdf
https://datascience.stackexchange.com/questions/38845/what-is-the-relationship-between-mdp-and-rl