Causal Intervention-based Class Activation Mapping
Published:
This paper explores the causalities among image features, contexts, and categories to eliminate the biased sobject-context entanglement in the class activation maps thus improving the accuracy of object localization.
概述
基于因果推断的CAM模型。主要解决在定位问题中,受到背景信息$C$纠缠从而使输入$X$和目标$Y$之间存在虚假相关性的问题
For example, if most “duck” appears concurrently with “water” in the images, thesetwo concepts would be inevitably entangled and wrongly generate ambiguous boundaries using only image-level supervision.
梳理
因果结构图
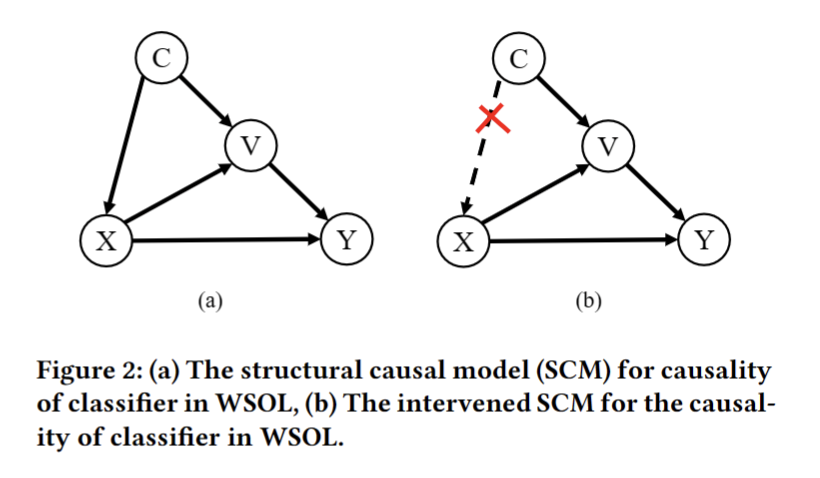
用$\rightarrow$代表因果关系,Figure 2展示的图结构因果模型解读如下
- $C \rightarrow X$:图像特征$X$受背景信息$C$影响
- 尽管干扰因素$C$可能有助于建立更完善的预测模,此时模型会在具有相关而不止因果关系的因素之间建立联系,类似“过拟合”
- $C\rightarrow V\leftarrow X$:$V$是基于$C$中的背景信息 (contextual template?) 的、针对每个图像特定的表征 (representation?)
- 这并非CI-CAM独有的概念;它支持了几乎所有概念学习 (concept learning) 方法,从Deformable Part Models到CNN
- $X\rightarrow Y \leftarrow V$:$X$和$Y$共同影响对图像标签$Y$的预测
- $V\rightarrow Y$:背景信息会影响图像标签。背景干扰因素$C$能且只能通过$C\rightarrow V\rightarrow Y$影响最终的预测$Y$
因果干涉
文章采用$P(Y\mid do(X))$作为image-level的分类器(即输出CAM的模块),从而移除干扰因素$C$、更好地建模$X$到$Y$真正的因果关系
Key Idea
- 切断联系$C\rightarrow X$
- 将$C$划分为$C={c_{1}, c_{2}, \cdots, c_{n}}$,其中$c_{i}$代表第$i$个类别的背景 所以有
其中$f(X, c)$是$C\rightarrow V\leftarrow X$的抽象表示, $n$是图像类别的数量。既然$C$不影响$X$,那么$X$很可能基于先验$P(c)$,将每种背景$c$的信息都整合进$Y$的预测里
- 为简化模型的前向传播,文章采用Normalized Weighted Geometric Mean以优化上式。具体而言,就是将外层的求和$\sum_{i}^{n}P(c_{i})$移到特征一层,由此,只需前向传播1次而非$n$次,即 \(P(Y \mid d o(X)) \approx P(Y \mid X=x, V=\sum_i^n f\left(x, c_i\right) P\left(c_i\right))\)
- 数据集中每一类别的样本量大致相同,所以文章设$P(c)\sim U(n)$,因而有进一步优化如下
其中$\oplus$即投影。到这里,“纠缠的背景” (entangled context) 问题就被转化为了计算$\sum_{i}^{n}f(x, c_{i})$。文章引入了causal context pool $Q$来表征$\sum_{i}^{n}f(x, c_{i})$
模型架构
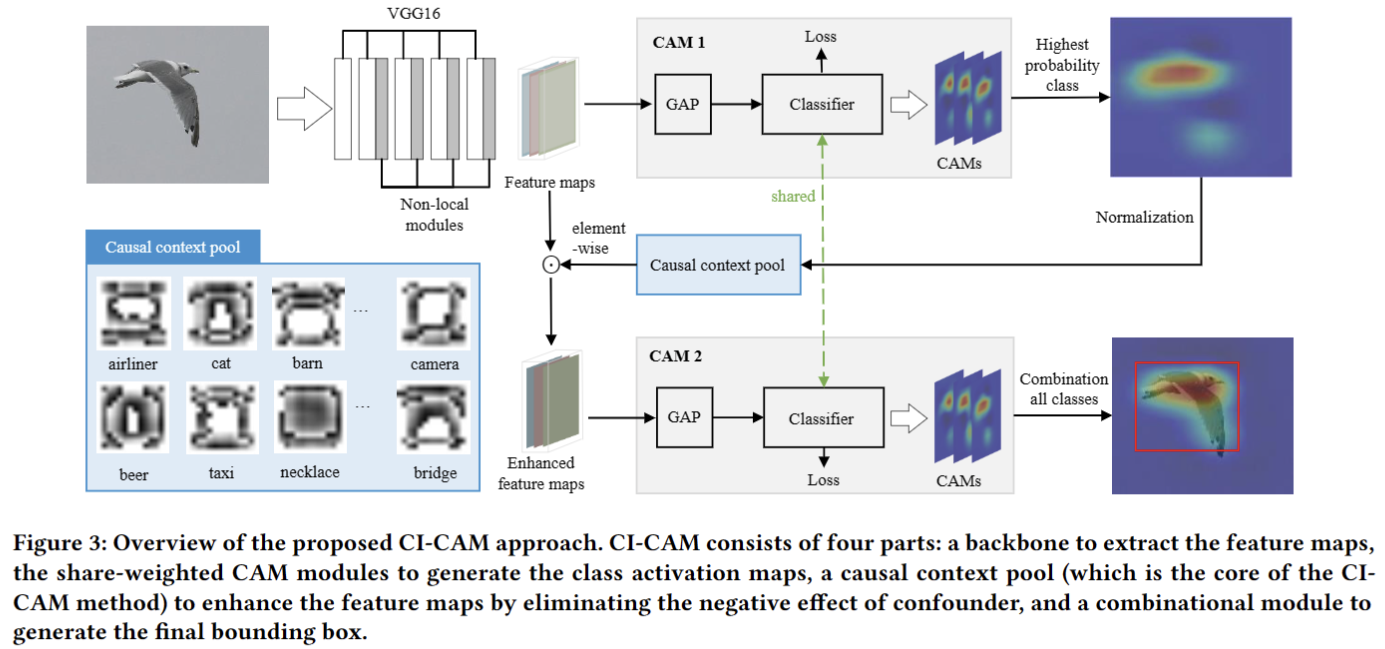
Causal Context Pool
在模型训练阶段,维护一个causal context pool $Q\in \mathbb{R}^{n\times h\times w}$,其中$Q_{i}$代表所有属于第$i$类别的图像的背景。
- $Q$会通过累积最高概率类别的activation map,不停存储每个类别的所有的contextual information maps
- 然后将每个类别的背景作为attentions投影到最后的卷积层输出的feature map上,以形成enhanced feature map
- 既可避免图像特征中的背景带来的负面影响,也能突出feature map的正向区域以提高定位能力
$Q$通过下式维护
\[Q_{\pi}=BN(Q_{\pi}+\lambda \times BN(M_{\pi}))\]其中$M$是class activation maps,$\pi=argmax({s_{1}, s_{2}, \cdots, })$,$\lambda$即更新比率。这其中$S={s_{1}, s_{2}, \cdots, s_{n}}$为第一个CAM分支产生的初始预测得分
思考
- 在稀疏小目标的定位上表现如何?
- 类别数量$n$的大小会不会有影响?
- 伪影与这里定义的“背景”有何关系?