Revision on 29th, Mar.
Published:
总体而言,我们从两个方面改进了之前的Deeplab V3+ & DANN分割模型
- 引入Tversky loss,以抑制在先前的实验中较为突出的假阳性问题
对模型训练使用的3个损失函数进行动态权值调整,以实现相对平衡的多目标优化
- Tversky Loss
- 多损失函数的权重自动调整
Tversky Loss
定义
Tversky loss是一种基于Tversky指数的损失函数,用于图像分割任务中的二分类或多分类问题。Tversky指数是一种类似于F1 score的指标,用于度量模型预测的准确率和召回率的平衡性。
在二分类任务中,Tversky loss的定义如下:
\[\begin{aligned} TL(y, \hat{y}) &= \frac{\sum\limits_{i=1}^{N}y_i\hat{y}_i}{\sum\limits_{i=1}^{N}(y_i\hat{y}_i + \alpha(1-y_i)\hat{y}_i + \beta y_i(1-\hat{y}_i))}\\ &=\frac{TP}{TP+\alpha \times FP+\beta\times FN} \end{aligned}\]其中,$y$表示真实标签,$\hat{y}$表示模型预测的标签,$\alpha$和$\beta$是两个超参数,用于控制准确率和召回率的平衡,通常有
\[\alpha+\beta=1\]与Dice loss相比,Tversky loss在平衡准确率和召回率方面更加灵活。Dice loss通过计算预测标签和真实标签的交集和并集来度量相似度,对于正样本和负样本的处理是一致的。而Tversky loss引入了两个超参数$\alpha$和$\beta$,通过加权正负样本的处理,可以更加精细地调整模型的学习目标,从而提高模型的性能。
与Dice loss
特别地,当$\alpha = \beta = 0.5$时,Tversky loss等价于Dice loss,如
\[\begin{aligned} TL(y, \hat{y}) &= \frac{\sum\limits_{i=1}^{N}y_i\hat{y}_i}{\sum\limits_{i=1}^{N}(y_i\hat{y}_i + \frac{1}{2}\times(1-y_i)\hat{y}_i + \frac{1}{2}\times y_i(1-\hat{y}_i))}\\ &=\frac{\sum\limits_{i=1}^{N}y_i\hat{y}_i}{\sum\limits_{i=1}^{N}(\frac{1}{2}\times \hat{y}_i + \frac{1}{2}\times y_i)}\\ &=\frac{2\times \sum\limits_{i=1}^{N}y_i\hat{y}_i}{\sum\limits_{i=1}^{N}(\hat{y}_i + y_i)} \end{aligned}\]而Dice loss通常记为
\[Dice(y, \hat{y})=\frac{2\times \sum\limits_{i=1}^{N}y_i\hat{y}_i}{\sum\limits_{i=1}^{N}\hat{y}_i + \sum\limits_{i=1}^{N}y_i}\]两者等价
与IOU
当$\alpha=\beta=1$时,Tversky退化为Jaccard系数,即交并比IOU
\[IOU(y, \hat{y})=\frac{|y_i\cap \hat{y}_i|}{|y_i\cap \hat{y}_i|+|\bar{y}_i\cap \hat{y}_i|+|y_i\cap \bar{\hat{y}}_i|}\]侧重假阳性
但当$\alpha$和$\beta$取其他值时,Tversky loss可以在一定程度上抑制假阳性,从而提高分割结果的质量。
举例而言,当$\alpha>\beta$时,项$(1-y_i)\hat{y}_i$权重高于项$y_i(1-\hat{y}_i)$。容易分析得到,项$(1-y_i)\hat{y}_i$衡量假阳性(false positive),项$y_i(1-\hat{y}_i)$衡量假阴性(false negative),那么此时损失函数更倾向于抑制假阳性。
在我们的模型中,我们取$\alpha=0.7$,$\beta=0.3$,实现了较好的效果。
总的来说,Tversky loss是一种灵活性更高的损失函数,可以根据具体任务调整超参数来平衡准确率和召回率,并在一定程度上抑制假阳性,从而提高模型的性能。
Focal Tversky Loss
基于Tversky loss的改进。引入超参数$\gamma$以非线性地控制hard sample和easy sample对loss的贡献,公式如下
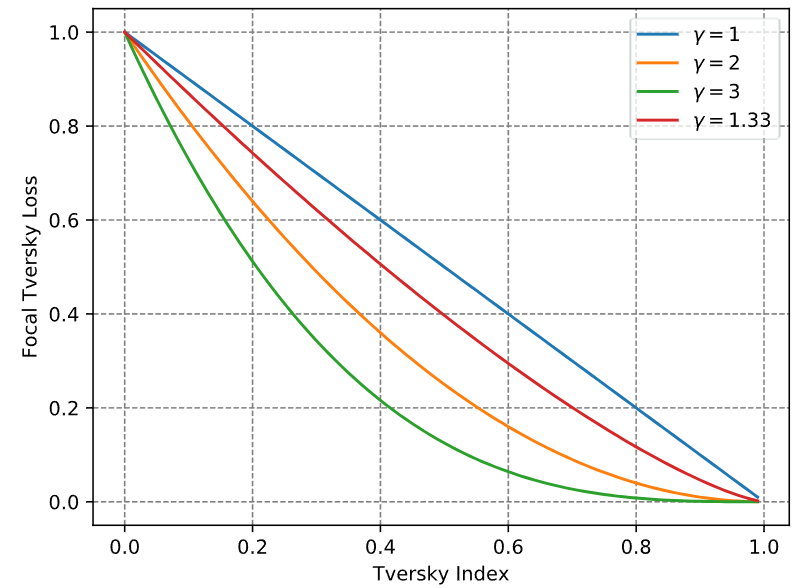
\[FTL(y, \hat{y})=(1-TL(y, \hat{y}))^{\frac{1}{\gamma}}\]原论文1中如下图所示,Focal Tversky Loss相对更关注hard sample (Tversky Index < 0.5),而抑制easy sample对loss的贡献程度
多损失函数的权重自动调整
背景
引入Tversky loss后,模型总体的损失函数就变成了3个loss的组合
- 分割部分
- Cross Entropy:交叉熵,用于衡量单个像素分类的精确度
- Tversky:用于评估空间范围内类别分布的一致性,且可通过参数$\alpha$和$\beta$调整对FP和FN的惩罚力度
- 域迁移部分
- Binary Cross Entropy:针对二分类的交叉熵,本质相同
3个loss直接组合构成了一个多目标优化问题。经验而言,它们直接相加会影响模型训练的收敛速度和效果(尤其是对参数量较大的模型)。所以我们引入了可学习的损失权重参数机制2
定义
在多目标优化的神经网络模型中,总损失函数可记为
\[\mathrm{L}_{\mathrm{comb}}\left(x, y_{\mathcal{T}}, y_{\mathcal{T}}^{\prime} ; \omega_{\mathcal{T}}\right)=\sum_{\tau \in \mathcal{T}} \mathrm{L}_\tau\left(x, y_\tau, y_\tau^{\prime} ; \omega_\tau\right) \cdot c_\tau\]其中,$\omega_{\mathcal{T}}=(\theta_{\mathcal{T}})$代表由与损失无关的可学习参数$\theta_{\mathcal{T}}$构成的模型,$x$即模型输入,$y_{\mathcal{T}}$为真实标签(Ground truth),$y_{\mathcal{T}}^{\prime}$为模型预测标签,$c_\tau$即各个loss的权重。与其手动调整权值$c_\tau$,我们可以把它作为模型需要学习的参数,加入模型,于是有
\[\omega_{\mathcal{T}}^{\prime}=(\theta_{\mathcal{T}}, c_{\mathcal{T}})\]这种做法同时也要求我们为总损失$L_{comb}$添加正则项$R(c_{\mathcal{T}})$以避免平凡解(0向量解)。论文中采用
\[R_{pos}(c_{\mathcal{T}})=\ln{(1+c_{\mathcal{T}}^2)}\]以强制要求正则项$>0$,进而避免当$c_{\mathcal{T}}<1$时模型出现负值损失。
综上,带有可学习、动态调整权值的多任务优化的总损失可记为
\[\begin{aligned} \mathrm{L}_{\mathcal{T}}\left(x, y_{\mathcal{T}}, y_{\mathcal{T}}^{\prime} ; \omega_{\mathcal{T}}\right)= & \sum_{\tau \in \mathcal{T}} [\frac{1}{2 \cdot c_\tau^2} \cdot \mathrm{L}_\tau\left(x, y_\tau, y_\tau^{\prime} ; \boldsymbol{\omega}_\tau\right)+\ln \left(1+c_\tau^2\right)] \end{aligned}\]使用PyTorch框架落实,大致即以下代码
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += 0.5 / (self.params[i] ** 2) * loss + torch.log(1 + self.params[i] ** 2)
return loss_sum
Abraham, N., & Khan, N. M. (2019, April). A novel focal tversky loss function with improved attention u-net for lesion segmentation. In 2019 IEEE 16th international symposium on biomedical imaging (ISBI 2019) (pp. 683-687). IEEE. ↩
Liebel, L., & Körner, M. (2018). Auxiliary tasks in multi-task learning. arXiv preprint arXiv:1805.06334. ↩